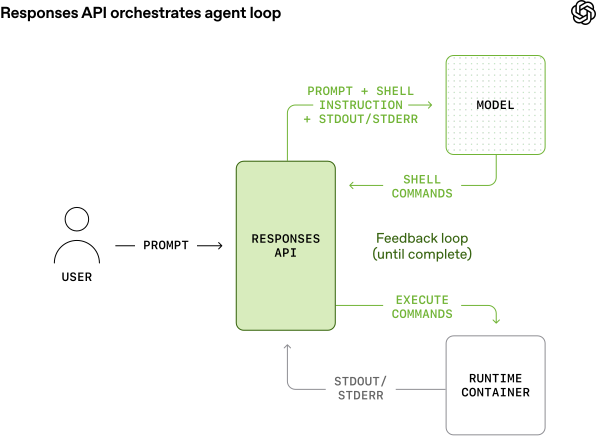
Building AI agents that do real work - not just chat but actually install packages, run scripts, and produce files - has required stitching together your own execution environment. OpenAI just published a detailed guide on how it built an agent runtime directly into the Responses API, and the three pieces fit together in a way that matters for anyone building production agents.
Shell: A Real Terminal for Models
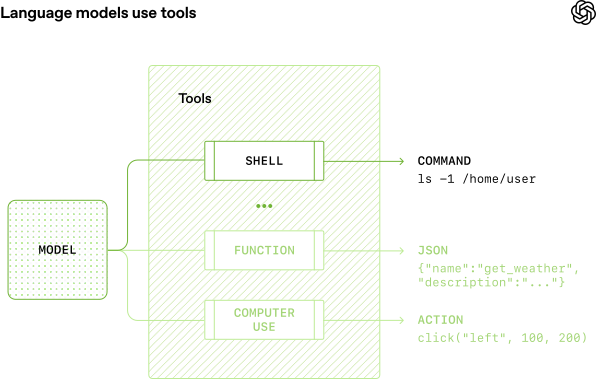
The shell tool gives models access to a complete terminal environment through the Responses API. You can run it two ways: hosted containers managed by OpenAI, or a local shell runtime you control.
The hosted option spins up a Debian 12 container with Python 3.11, Node.js 22, Java 17, Go 1.23, and Ruby 3.1 pre-installed. Files persist at /mnt/data, so agents can generate artifacts, save them, and let you download them. Containers expire after 20 minutes of inactivity, and OpenAI discards everything when they do - so you need to pull your files before that window closes.
Networking is locked down by default. No outbound access unless an org admin configures an allowlist, and even then each API request must explicitly declare which domains the agent can reach. Credentials are handled through "domain secrets" - the model sees placeholder names like $API_KEY while the runtime injects real values only for approved destinations. This is a sensible security model for letting agents interact with third-party services without exposing secrets in the conversation.
Skills: Reusable Instructions That Travel With Agents
Skills are versioned instruction bundles with a manifest file that you mount into containers. Think of them as SOPs (standard operating procedures) for AI agents - they contain workflows, templates, and guardrails the model can consult when executing specific tasks. A Salesforce-oriented skill, for example, improved task accuracy from 73% to 85% and reduced time-to-first-token (how fast the model starts responding) by 18.1% in testing with enterprise search company Glean.
The practical advice from OpenAI's blog post: write skill descriptions with explicit routing logic, include "use when / don't use when" blocks, and add negative examples to reduce misfiring.
Compaction: Solving Context Amnesia
Server-side compaction is the piece that makes long-running agents viable. As an agent works through a multi-step task, the conversation history grows until it hits the model's context window limit (the amount of text it can "remember" at once). Compaction automatically compresses past actions into a summary, keeping the agent functional over extended sessions. OpenAI reports agents successfully handling 5 million token sessions across 150+ tool calls without accuracy degradation.
That 5 million token figure is significant. A single context window for GPT-4o is 128,000 tokens. Compaction effectively gives agents ~39x that working memory by intelligently summarizing what came before.
For developers already building on the Responses API, these three features together remove the biggest pain point: agents that lose track of what they were doing mid-task. The shell tool is not available through the older Chat Completions API, so this is another nudge toward the Responses API as OpenAI's preferred interface for agent development.