The Claude model landscape changed dramatically with Opus 4.5. What was once a premium-only model is now just 1.7x the cost of Sonnet - down from 5x. Combined with Haiku for high-volume tasks, developers now have a three-tier strategy that optimizes both quality and cost. Anthropic continues to refine their model pricing to make advanced AI more accessible.
If you’re asking which claude model for coding is the right pick, this guide covers when to use Opus, Sonnet, or Haiku based on real-world coding scenarios, updated for 2026 pricing.
Methodology
Anthropic’s February 2025 pricing update fundamentally changed the economics of model selection:
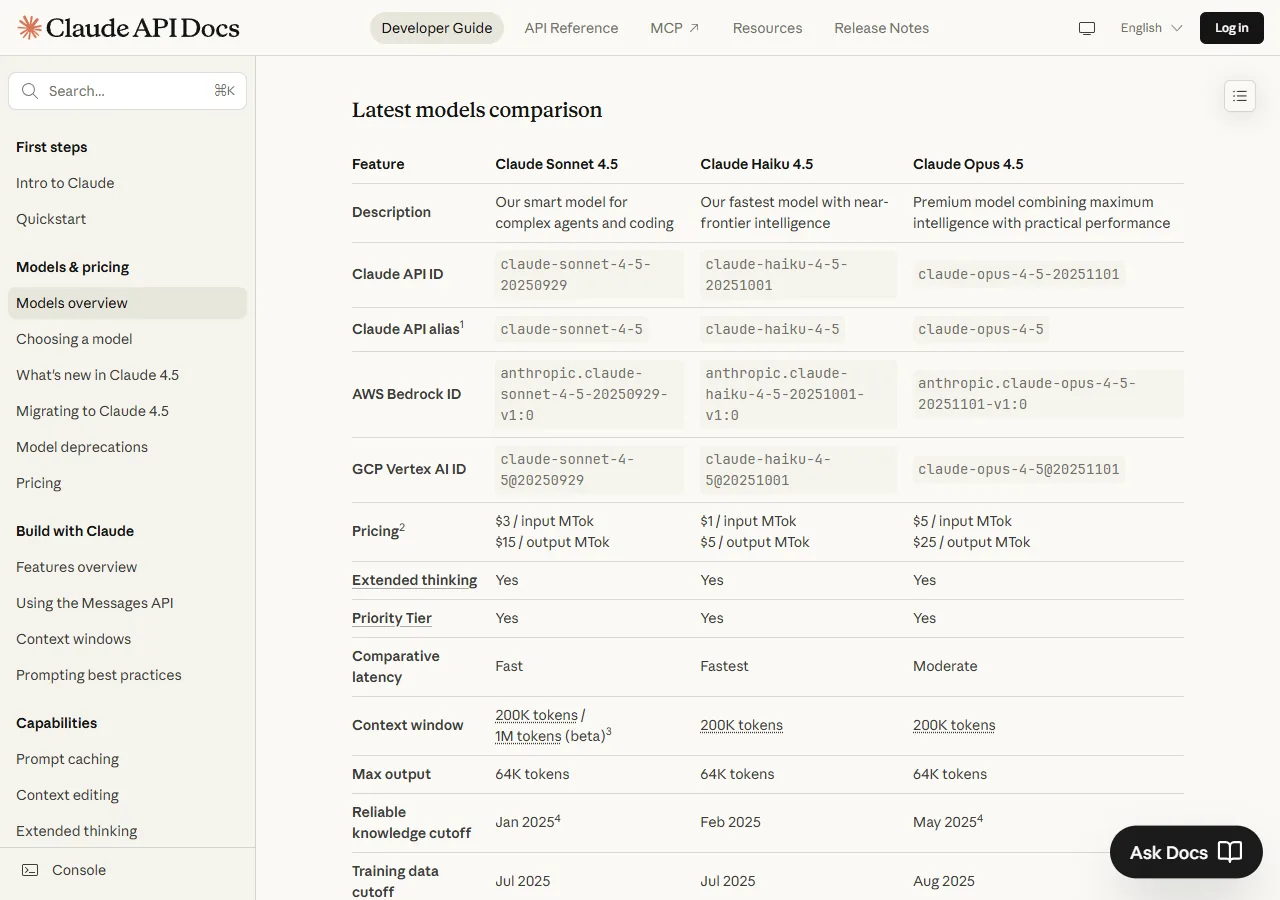
| Model | Input (1M tokens) | Output (1M tokens) | Relative Cost |
|---|---|---|---|
| Opus 4.5 | $5 | $25 | 1.7x Sonnet |
| Sonnet 4 | $3 | $15 | Baseline |
| Haiku 3.5 | $1 | $5 | 0.3x Sonnet |
The old calculus is obsolete. Previously, Opus at $15/$75 meant using it sparingly for only the most complex tasks. At $5/$25, Opus becomes viable for any task where quality matters - code reviews, architecture decisions, debugging, and security analysis.
Haiku, often overlooked, fills the gap for high-volume, routine tasks where speed and cost efficiency beat raw capability.
The Models at a Glance: Which Claude Model for Coding Tasks
Claude Opus 4.5
Anthropic’s flagship model. Opus excels at:
- Complex architectural reasoning
- Multi-file refactoring with consistency
- Security vulnerability detection
- Nuanced code review feedback
- Debugging subtle race conditions and edge cases
Best for: Tasks where getting it right the first time saves iteration cycles.
Claude Sonnet 4
The balanced workhorse. Sonnet handles:
- Most day-to-day coding tasks
- Feature implementation with clear requirements
- Test generation
- Documentation
- Straightforward debugging
Best for: 80% of development work where speed and quality both matter.
Claude Haiku 3.5
The efficiency specialist. Haiku excels at:
- Boilerplate generation
- Syntax transformations
- Code formatting and linting suggestions
- High-volume batch operations
- Quick lookups and explanations
Best for: Simple, well-defined tasks where speed and cost dominate.
Limitations and who it’s not for: Skip Opus 4.5 if your daily workload is mostly mechanical syntax work, since you will pay 1.7x Sonnet pricing for marginal gains. Skip Sonnet if you need bulk batch jobs or near-instant tab completion - Haiku is faster and cheaper for those. Skip Haiku for any multi-file refactor or security-sensitive review, since coherence and depth fall off sharply. Cons shared across all three: knowledge cutoffs lag current frameworks by months, and none of these models autonomously test their own output without an external runner.
How Do Claude Models Perform by Coding Task Type?
Code Generation
| Task Type | Haiku | Sonnet | Opus |
|---|---|---|---|
| Simple functions | Good | Excellent | Excellent |
| CRUD endpoints | Good | Excellent | Excellent |
| Complex algorithms | Adequate | Good | Excellent |
| Multi-file features | Poor | Good | Excellent |
| Architecture design | Poor | Adequate | Excellent |
Simple functions: All three models handle well-defined utility functions. Haiku produces working code fastest. Sonnet adds better edge case handling. Opus rarely provides meaningful improvement here.
Task: "Create a function to validate email addresses"
Haiku: Good - fast, functional
Sonnet: Excellent - better edge cases
Opus: Excellent - same quality, slower
Winner: Haiku or Sonnet (cost/speed vs quality tradeoff)Complex algorithms: Opus demonstrates clear advantages. It produces more elegant solutions, considers edge cases unprompted, and writes better-optimized code.
Task: "Implement a LRU cache with O(1) operations"
Haiku: Functional but basic
Sonnet: Good - solid implementation
Opus: Excellent - cleaner design, better memory efficiency
Winner: Opus (measurably better quality)Multi-file features: For features spanning multiple files with interdependencies, Opus maintains consistency and makes smarter architectural decisions. Haiku struggles with context across files.
Task: "Add user authentication with JWT, refresh tokens, and role-based access"
Haiku: Poor - loses consistency across files
Sonnet: Good - works but may need corrections
Opus: Excellent - cohesive architecture, fewer iterations
Winner: Opus (significantly better coherence)Code Review and Debugging
| Task Type | Haiku | Sonnet | Opus |
|---|---|---|---|
| Syntax errors | Good | Good | Good |
| Logic bugs | Adequate | Good | Excellent |
| Security vulnerabilities | Poor | Good | Excellent |
| Performance issues | Poor | Adequate | Excellent |
| Architecture review | Poor | Adequate | Excellent |
Finding bugs: Sonnet identifies obvious bugs effectively. Opus excels at finding subtle issues - race conditions, security vulnerabilities, and logic errors requiring deep understanding.
Security analysis: Opus’s reasoning depth catches vulnerabilities that other models miss. For security-sensitive code, the quality difference justifies the cost.
Refactoring
Simple refactors: Renaming, extracting functions, and mechanical transformations work well across all models. Use Haiku for maximum efficiency.
Complex refactors: When refactoring involves changing fundamental approaches or understanding business logic implications, Opus produces cleaner results with fewer broken dependencies.
Limitations and who it’s not for: Performance ratings on this table are not absolute. Skip benchmarks here if your stack relies on niche languages (Elixir, Zig, Roc) - all three models trail their Python and TypeScript performance on less-common ecosystems. Cons of relying on tier-based generation include Haiku producing functional but uncreative solutions, and Opus over-engineering simple problems with patterns that bloat code. Drawbacks across the board: code-review accuracy degrades sharply on private codebases that differ from open-source training patterns.
Speed and Latency
Real-world timing comparison:
| Task Type | Haiku | Sonnet | Opus |
|---|---|---|---|
| Simple function | 1-2s | 2-4s | 5-10s |
| Complex function | 2-4s | 5-10s | 15-30s |
| Multi-file changes | 5-10s | 15-30s | 45-90s |
| Code review | 2-5s | 5-15s | 20-45s |
For interactive development: Haiku and Sonnet’s speed compounds across iteration cycles. Each iteration being faster means better flow state.
For background tasks: Opus’s thoroughness becomes more valuable when latency doesn’t impact your workflow.
Limitations and who it’s not for: Latency numbers above are best-case. Skip Opus for any keystroke-driven flow like tab completion or live pair programming, since 15-90 second waits break concentration. Skip Sonnet for high-throughput batch pipelines where Haiku’s 1-2s simple-function speed cuts wall-clock time dramatically. Cons across all tiers: API rate limits and cold-start delays add unpredictable overhead during peak hours, and streaming responses still pause noticeably on Opus when reasoning chains grow long.
How Do Opus, Sonnet, and Haiku Compare on Pricing?
The pricing change creates new economic considerations:
Old reality (Opus at $15/$75):
- 100 Sonnet requests ~= 20 Opus requests (same budget)
- Opus reserved for special occasions
New reality (Opus at $5/$25):
- 100 Sonnet requests ~= 60 Opus requests (same budget)
- Opus viable for any quality-sensitive work
Haiku advantage:
- 100 Sonnet requests ~= 300 Haiku requests
- Massive savings on high-volume, simple tasks
Cost-per-task comparison
For a typical coding session (10,000 input tokens, 2,000 output tokens per task):
| Model | Cost per Task | Tasks per $10 |
|---|---|---|
| Opus 4.5 | $0.10 | 100 |
| Sonnet 4 | $0.06 | 167 |
| Haiku 3.5 | $0.02 | 500 |
Choose Haiku if
Optimal scenarios for Haiku:
- Boilerplate generation - Repetitive scaffolding, templates
- Syntax transformations - Format conversions, type annotations
- Linting and formatting - Style suggestions, code cleanup
- High-volume batch jobs - Processing many files identically
- Quick explanations - “What does this regex do?”
- Simple completions - Finishing obvious patterns
Example workflow:
Developer: "Add TypeScript types to these 50 utility functions"
→ Haiku processes all 50 in parallel
→ Cost: ~$0.50 vs $3 with Sonnet
→ Quality: Sufficient for mechanical transformationsFor production-grade TypeScript development, this efficiency compounds across hundreds of daily tasks.
When NOT to use Haiku:
- Tasks requiring cross-file consistency
- Security-sensitive code
- Complex business logic
- Anything where “good enough” isn’t good enough
Choose Sonnet if
Optimal scenarios for Sonnet:
- Feature implementation - New functionality with clear requirements
- Test generation - Unit tests, integration tests
- Interactive development - Rapid iteration cycles
- Documentation - Comments, README updates, API docs
- Debugging standard issues - Obvious bugs, error traces
- Learning and exploration - Quick experiments, trying approaches
Example workflow:
Developer: "Create a React component for user profile editing"
→ Sonnet generates component in 3 seconds
→ Developer reviews, requests tweaks
→ Sonnet updates in 2 seconds
→ Total: 5 seconds, excellent resultChoose Opus if
Optimal scenarios for Opus:
- Complex architecture - System design, major refactors
- Security-sensitive code - Authentication, encryption, data handling
- Debugging difficult issues - Subtle bugs, race conditions
- Code review - Thorough analysis of important changes
- Ambiguous requirements - Tasks needing interpretation
- Novel problems - Unusual challenges without established patterns
- Multi-file consistency - Features touching many interconnected files
Example workflow:
Developer: "Review this authentication system for security issues"
→ Opus analyzes in 30 seconds
→ Identifies 3 subtle vulnerabilities Sonnet missed
→ Provides remediation with security rationale
→ Total: 30 seconds, potentially critical findingsHow Should You Apply a Three-Tier Claude Model Strategy?
Deciding which claude model for coding comes down to matching task complexity to model capability. Here’s a simple flowchart.
Decision Flowchart
┌─────────────────────────────────────────────┐
│ TASK ARRIVES │
└─────────────────────┬───────────────────────┘
│
▼
┌─────────────────────────────────────────────┐
│ Is it mechanical/repetitive? │
└─────────────────────┬───────────────────────┘
│
┌──────────┴──────────┐
│ YES │ NO
▼ ▼
┌─────────┐ ┌─────────────────────────┐
│ HAIKU │ │ Does it require deep │
└─────────┘ │ reasoning or security? │
└─────────────┬───────────┘
│
┌──────────┴──────────┐
│ YES │ NO
▼ ▼
┌─────────┐ ┌─────────┐
│ OPUS │ │ SONNET │
└─────────┘ └─────────┘Quick Reference
| Indicator | Model |
|---|---|
| ”Just format this” | Haiku |
| ”Add types to these files” | Haiku |
| ”Generate CRUD endpoints” | Haiku or Sonnet |
| ”Implement this feature” | Sonnet |
| ”Write tests for this” | Sonnet |
| ”Review this PR” | Opus |
| ”Debug this race condition” | Opus |
| ”Design the auth system” | Opus |
| ”Check for security issues” | Opus |
Escalation Pattern
Start simple, escalate when needed:
- Default assessment - Categorize task complexity
- Initial attempt - Start with appropriate tier
- Quality check - Review output critically
- Escalate if needed - Move up a tier for complex cases
- Learn patterns - Track which tasks need which tier
Limitations and who it’s not for: A three-tier strategy is not for everyone. Skip the routing approach if your team is small enough that a single default model keeps mental overhead lower than the cost savings. Cons include the engineering cost of building a classifier that picks the right tier, brittle escalation logic that breaks when model versions update, and the fact that real-world tasks rarely fit clean tiers - many sit on the boundary between Sonnet and Opus. Drawbacks for solo developers: context-switching between three model behaviors can be more disruptive than the cost savings recover.
Tool-Specific Implementation
Claude Code (CLI)
# Default configuration (Sonnet)
claude "create user validation function"
# Explicitly use Opus for complex tasks
claude --model opus "review this authentication system"
# Use Haiku for batch operations
claude --model haiku "add JSDoc comments to all functions in utils/"Configure defaults in settings for automatic tier selection.
Cursor IDE
Configure model selection per-context:
- Tab completion: Haiku (speed critical)
- Quick edits: Sonnet
- Composer (multi-file): Opus
- Chat/review: Opus
API Integration
def get_model_for_task(task_type: str, complexity: str) -> str:
"""Select optimal Claude model based on task characteristics."""
# Haiku for mechanical tasks
if task_type in ["format", "lint", "annotate", "boilerplate"]:
return "claude-3-5-haiku-20241022"
# Opus for complex/security-sensitive
if complexity == "high" or task_type in ["review", "security", "architecture"]:
return "claude-opus-4-5-20250120"
# Sonnet for everything else
return "claude-sonnet-4-20250514"Limitations and who it’s not for: Tool-specific configuration has its own tradeoffs. Skip the per-tool model routing if you primarily work in GitHub Copilot on a Business plan that enforces a single model, since per-context overrides require an enterprise tier. Skip Cursor’s composer routing if your codebase has weak file boundaries - Opus loses context fidelity faster than the docs imply on monolithic files. Cons of Claude Code CLI configuration include the need to track usage per model in your billing dashboard, and the lack of a UI hint when an Opus call silently exceeds your monthly cap.
Best Picks by Use Case
Scenario 1: Building a New Feature
Task: Add shopping cart functionality to e-commerce site
Three-tier approach:
- Architecture planning (Opus) - Design cart data model, API structure, state management
- Boilerplate (Haiku) - Generate base component files, types, interfaces
- Implementation (Sonnet) - Build cart service, components, routes
- Testing (Sonnet) - Generate comprehensive test cases
- Review (Opus) - Final security and architecture review
Result: Opus ensures solid foundation, Haiku handles scaffolding, Sonnet implements efficiently.
Scenario 2: Debugging Production Issue
Task: Users intermittently can’t complete checkout
Three-tier approach:
- Initial analysis (Opus) - Review logs, identify potential causes
- Add logging (Haiku) - Quick instrumentation across files
- Hypothesis testing (Sonnet) - Implement and test quick fixes
- Root cause analysis (Opus) - Deep dive into race condition
- Fix implementation (Sonnet) - Apply the fix
- Fix verification (Opus) - Review fix for completeness
Result: Opus finds subtle issues, Haiku handles mechanical work, Sonnet implements solutions.
Scenario 3: Large-Scale Refactoring
Task: Migrate codebase from JavaScript to TypeScript
Three-tier approach:
- Strategy (Opus) - Plan migration approach, identify risky areas
- Type generation (Haiku) - Add basic types across files
- Complex types (Sonnet) - Handle generic types, interfaces
- Architecture types (Opus) - Design type system for complex domains
- Verification (Sonnet) - Test and fix type errors
Result: Haiku handles volume, Sonnet manages complexity, Opus ensures correctness.
What Are the Most Common Claude Model Selection Mistakes?
Mistake 1: Always Using One Model
Problem: Missing optimal cost/quality tradeoffs
Fix: Match model to task characteristics. A three-tier approach saves money AND improves quality.
Mistake 2: Using Haiku for Complex Tasks
Problem: Poor output quality, more iterations, technical debt
Fix: Reserve Haiku for truly mechanical tasks. If it requires judgment, use Sonnet minimum.
Mistake 3: Using Opus for Everything
Problem: Slower development, unnecessary costs
Fix: Most tasks don’t need Opus’s depth. Save it for architecture, security, and debugging.
Mistake 4: Ignoring the New Pricing
Problem: Still treating Opus as “special occasions only”
Fix: At 1.7x Sonnet cost, Opus is viable for any quality-sensitive work. Recalibrate your defaults.
Mistake 5: Switching Models Mid-Task
Problem: Context loss, repeated explanations, inconsistent output
Fix: Assess complexity upfront, commit to model choice for the task.
Selection Criteria
Create your own comparison data:
- Track task types - Categorize your common tasks
- A/B test models - Try different tiers on similar tasks
- Measure outcomes - Time, quality, iterations, cost
- Build decision rules - Formalize what works for your codebase
Sample tracking template:
| Date | Task | Model | Time | Iterations | Quality | Cost | Notes |
|------|------|-------|------|------------|---------|------|-------|
| 2/1 | API endpoint | Sonnet | 5s | 1 | Good | $0.06 | Standard CRUD |
| 2/1 | Auth review | Opus | 45s | 1 | Excellent | $0.10 | Found XSS issue |
| 2/1 | Add types | Haiku | 2s | 1 | Good | $0.02 | Batch job |Conclusion
Now you know which claude model for coding fits each scenario. The three-tier Claude strategy maximizes value across the capability-cost spectrum:
Haiku (30% of tasks): Mechanical work, batch operations, simple completions. Fast and cheap.
Sonnet (50% of tasks): Daily development - feature implementation, testing, debugging standard issues. The reliable workhorse.
Opus (20% of tasks): Architecture, security, complex debugging, code review. Worth the premium for tasks where quality compounds.
The new Opus pricing changes everything. At 1.7x Sonnet instead of 5x, quality-sensitive work should default to Opus. Combined with Haiku for volume tasks, you get better results at lower total cost than a single-model approach.
The winning strategy:
- Categorize tasks by complexity and security sensitivity
- Match each category to the appropriate tier
- Track outcomes to refine your decision rules
- Don’t be afraid to use Opus - the pricing now supports it
All three models are remarkable tools. Whether you access them through Claude Code, GitHub Copilot, or Cursor, using them strategically maximizes their collective value while respecting your time and budget.
FAQ
Q: Is Claude 4 or 3.5 better for coding?
Now you know which claude model for coding fits each scenario. The three-tier Claude strategy maximizes value across the capability-cost spectrum:
Q: Is Claude 3.7 or 4 better for coding?
Now you know which claude model for coding fits each scenario. The three-tier Claude strategy maximizes value across the capability-cost spectrum:
Q: Is Claude 4 the best at coding?
Now you know which claude model for coding fits each scenario. The three-tier Claude strategy maximizes value across the capability-cost spectrum:
Q: How to choose which model to use in a Claude code?
Now you know which claude model for coding fits each scenario. The three-tier Claude strategy maximizes value across the capability-cost spectrum:
Related Reads
Tradeoffs: Each Claude model has limitations - explore more Claude coding content for the right fit:
- Claude Review - Full review of Anthropic’s AI assistant
- Claude Code Review - CLI-based AI coding assistant
- Cursor Review - AI-first code editor
- GitHub Copilot Review - AI pair programmer
- Claude Code Prompt Engineering - Master prompting techniques for better code generation
- Claude Code Hooks Deep Dive - Automate workflows with custom hooks
- Best AI Coding Assistants 2026 - Compare Claude with GitHub Copilot, Cursor, and more
- GitHub Copilot vs Cursor vs Gemini - Head-to-head IDE comparison
- 5 Best AI Tools for Coding in 2026
- Future of AI Coding Assistants: 4 Tools Shaping Development in 2026
- JetBrains AI Assistant: Complete Guide to AI Pro & Ultimate
External Resources
Official documentation and pricing:
- Claude API Pricing - Current model pricing
- Claude Documentation - Official API docs and guides
- Claude Model Overview - Model capabilities and specifications